RAID: In the context of the increasing importance of data in making decisions and solving various problems, both for oneself and for organizations, its credibility and accessibility should be the central values in the digital environment. RAID stands for Redundant Array of Independent Disks, the redundantly joining physically distinct disks to act as one or more disks. It focuses on optimizing the reliability of the memory and the performance resulting from concurrent access to disks. This system guards against adverse hardware conditions and guarantees data integrity even if a disk is damaged; it can increase the I/O rate for applications that require high performance.
For Linux, software RAID is quite flexible and affordable compared to its counterparts and is managed with the help of mdadm tools. This blog describes different RAID levels, the benefits and drawbacks of each, and a guide on creating RAID arrays using mdadm. Performance and custom configuration options are also part of our guide; we explain them and their relevance for enterprise settings. That way, by the end of the video, you’ll know how to use RAID in Linux for data backup and enhancing the functionality of a system.
Table of Contents
What is RAID?
RAID, or Redundant Array of Independent Disks, is a virtualization of data storage technology that combines several physical disk drives into one or more logical ones. This is done to improve performance. Field of Study: Computer Science induces high availability or increases the resilience of the storage system against disk drive failures. Thus, RAID’s goal is to improve data dependability and efficiency, and it achieves this by distributing data across several disks.
History of RAID:
RAID, an acronym originally coined by David A. Patterson, Garth A. Gibson, and Randy H. Katz at Berkeley in 1988, originally it was called as “Redundant Arrays of Inexpensive Disks.” They introduced the concept of focusing on the use of multiple inexpensive disks working together to provide redundancy and improve performance.
Over time, as disk prices dropped and the technology became more accessible, the “I” in RAID began to be interpreted as “Independent” instead of “Inexpensive.” This change reflects RAID’s broader application beyond cost-saving measures, emphasizing its role in enhancing data storage reliability and performance. Despite this evolution, both interpretations of the acronym are still used today.
RAID was developed to address the growing disparity between input/output (I/O) capabilities and processing power. Patterson, Gibson, and Katz observed that while CPU speed and memory capacity were increasing exponentially, disk performance was improving at a much slower, linear rate.
To tackle this issue, their Berkeley Papers proposed moving away from the use of a Single Large Expensive Disk (SLED). Instead, they suggested using multiple smaller disks combined to function as a single, larger disk, which could be accessed seamlessly by operating systems and applications. This approach aimed to enhance overall system performance and reliability.
RAID offers solutions to a wide range of challenges faced by various organizations. For instance, some organizations might need to manage vast amounts of data, such as newsgroup postings, which, while not critical, require substantial storage capacity. In these cases, a single hard drive would be insufficient, and manually organizing the data would be impractical. On the other hand, some companies handle smaller quantities of highly sensitive data, where any downtime or data loss could have severe consequences. RAID’s flexibility and diverse configurations allow it to be adapted to meet the needs of both these scenarios and many others, making it a valuable tool for organizations with different data storage requirements.
Key Objectives of RAID
- Data Redundancy: RAID is a way of making a logical unit or a portion of it redundant by copying the data or using parity information in case of a disk failure. This means data is always retrievable and remains accurate in case one or more drives fail.
- Performance Enhancement: RAID increases the I/O capability by providing data striping methods for performing read and write operations simultaneously on the disks. This is advantageous for programs that involve data streaming at high levels, such as video editing programs or large web servers.
- Scalability and Flexibility: RAID also facilitates adding more disks to enhance the storage capability while preserving the data well laid. This means that the system allows for the permutation of the array to suit one’s capacity, performance, or even redundancy preference.
Types of RAID
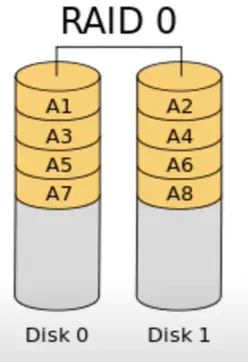
RAID 0 (Striping):
It is also called as stripping. Data is divided into blocks, and each block is written on all the disks in the array.
In data striping, data is distributed across multiple disks, with a fixed portion of data written to each disk. The first disk in the array remains inactive until an equivalent amount of data is written to all other disks in the array. This method boosts read and write speeds by enabling simultaneous data writing across multiple drives.
The total amount of data written across the disks is referred to as the stripe size. For instance, with a stripe size of 64KB spread across four disks, each disk would receive 16KB of data.
The smallest portion of data that can be written to a single disk during one write operation is known as the chunk size. In this example, the chunk size is 16KB, which together forms the 64KB stripe size.
Advantages: Persistent and carrying out parallel data access, giving high performance.
Disadvantages: If one disk fails, all data is lost.
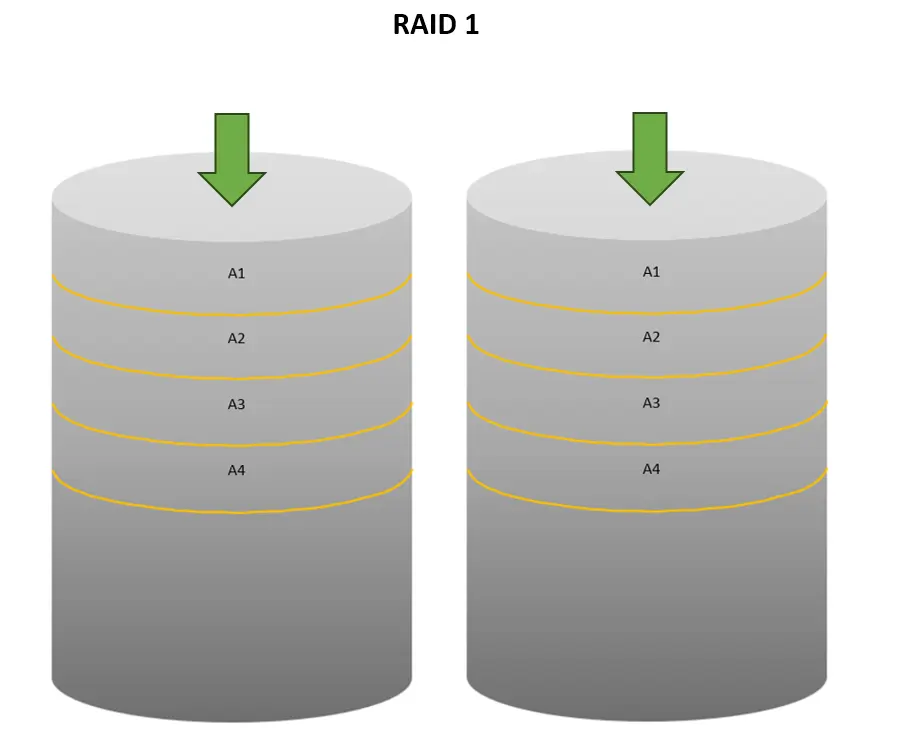
RAID 1 (Mirroring):
Raid 1 is also called as mirroring. Mirroring involves creating identical copies of data on every disk within a group, ensuring that each disk contains the same information and is equally crucial. If one disk fails, the data can still be accessed from the other disks, providing redundancy.
This approach enhances read performance because data can be read from multiple disks simultaneously, much like reading from multiple copies of the same book at once. For example, with two mirrored disks, read speeds can potentially double compared to using a single disk. However, this speed boost may not be fully realized in practice due to factors like file system performance and data distribution.
On the other hand, writing data in a mirrored setup takes longer since the information must be written to each disk in the group. Therefore, while mirroring speeds up reading, it can slow down writing compared to using a single disk.
Advantages: Enables the generation of a precise copy of the data on two or more disks yields high redundancy and short read and write times.
Disadvantages: It reduces storage space; the minimum number of disks to use is two, thus doubling the cost.
RAID 2 (Bit-Level Striping):
In RAID 2 data is divided into bits and it is distributed on all the disks. In this technology, hamming codes are used for error correction. Separate disk is required for the error correction code (ECC). This provides fault tolerance of one disk, Until the disk is replaced the system will continue to work.
However due to large overhead, low efficiency and its complexity, It is rarely used now a days.
RAID 3 (Byte-Level Striping):
In RAID 2 data is divided into bytes and it is distributed on all the disks. For parity dedicated disk is used.
It can afford the disk loss of one disk.
RAID 4 (Block Level Striping):
Data is divided into blocks and striped on all the disks. There is a separate disk for parity.
Minimum of 3 disks are required for the RAID 3 to be useful. It provides good performance for the random reads and low performance for the random writes.
RAID 5 (Striping with Parity):
Strips the data and parity information across three or more disks.
Advantages: It reflects equilibrant, parallel replication, and power of charisma compared to storage capability in a system. It enables the use of your data even if a single disc in the array is damaged.
Disadvantages: The write operations might be reduced due to parity calculations; they should have at least three disks.
RAID 6 (Striping with Double Parity):
This is similar to RAID 5, but the level has an extra parity block containing the second copy of the parity information.
Advantages: It can withstand two disk failures simultaneously, hence the higher degree of RAID.
Disadvantages: In overhead, write performance is affected; it requires at least four disks.
RAID 10 (RAID 1+0):
It is produced by coupling RAID 1, where disks are mirrored, and then RAID 0, which is used to stripe the mirrored disks.
Advantages: It has high performance and is also highly redundant. If not in the mirrored pairs, different disks can go bad at the same time.
Disadvantages: The issuing of a disk version will require purchasing twice the number of disks, which will lead to a higher cost.
RAID Implementation Methods
- Hardware RAID: Employ a separate card capable of handling the RAID configuration apart from the computer. This option comes with features like hot-swapping and data encryption at the hardware level. However, it is expensive and may not be compatible with other software from other companies.
- Software RAID: This is conducted by the operating system, with assistance from programs like mdadm in the Unix/Linux environment. It is less fixed and cheaper but shares the workload with the host system’s CPU, which can take a toll at high loads.
As one of the widely used technologies, RAID enriches data storage systems by boosting their performance and introducing redundancy. The RAID level and the method of its implementation should be chosen depending on needs and concerns about cost, level of difficulty, data protection, and performance.
Software RAID in Linux
Software RAID is the execution of RAID via the operating system, with the help of which RAID can be performed without using any specialized hardware devices. Software RAID on the Linux system is coordinated by tools such as mdadm (Multiple Device Administrator). This approach is widely used because it is cheap, effective, and easily configurable, both for private persons and for companies.
Advantages of Software RAID
- Cost-Effectiveness: Unlike hardware RAID, which requires a RAID controller card, software RAID can be configured using the computer’s system resources. This makes it a cost-effective file-sharing method, especially for small businesses and home users.
- Flexibility: It must also be noted that SOFTWARE RAID is more flexible in terms of implementing and managing the RAID arrays. There are no compatibility issues with the hardware, and users can manage RAID configurations, erase arrays, and replace failed disks.
- Portability: Software RAID arrays do not belong to a particular hardware controller; thus, they are not fixed on any particular system. This portability is a great plus when it comes to system upgrades and migrations because instance modules do not have to be loaded from scratch.
- Scalability: This design allows for the addition of additional drives to the existing RAID set-up or the formation of new sets as storage requirements increase. Software RAID is ideal in this regard because the structures that hold data can be scaled up or down depending on current needs.
- Management and Monitoring: Linux offers powerful software to create, manage, and check the health of the RAID, for instance, mdadm. These tools include reporting and alerting and assist the administrators in monitoring the state and efficiency of the storage system.
mdadm: The Tool for Software RAID Management
This type of RAID is managed by the mdadm tool, which is considered the most popular software RAID in Linux. It offers an integrated set of functions to create, configure, host, and supervise RAID sets. Here’s an overview of how to use mdadm: Here’s an overview of how to use mdadm:
Installing mdadm
mdadm is usually available in the packages where any Linux distribution is stored. To install it, they are recommended to use the package manager for the distribution they use.:
sudo apt install mdadm
# For Ubuntu/Debian Ossudo yum install mdadm
# For Red Hat/CentOSCreating a RAID Array
When creating a new RAID array, the RAID level has to be entered/known, and the devices and other options must also be entered. Here’s how you can create a RAID 1 (mirroring) array:
- Identify the Devices: To begin with, defining the devices you plan to employ is essential. This can be done using the ‘lsblk’ or ‘fdisk -l’ commands. An example of using the ‘lsblk’ command to view the block devices is as follows:
- Create the Array: To create the array, use the mdadm command. The contents of the file for a RAID 1 array with two devices /dev/sda and /dev/sdb:
sudo mdadm --create --verbose /dev/md0 –level=1 –raid-devices=2 /dev/sda /dev/sdbThis command forms a RAID 1 array identified as /dev/md0.
Formatting and Mounting the RAID Array
After the RAID array has been created, it must be formatted with an FS, and then it can be mounted to a directory:
- Format the Array: This array has to be formatted like ext4 in a filesystem:
sudo mkfs.ext4 /dev/md0- Mount the Array: Make a mount point and mount the array:
sudo mkdir -p /mnt/raid1sudo mount /dev/md0 /mnt/raid1- Automount on Boot: Next, to have the RAID array automatically mount at booting, create an entry for it in /etc/fstab:
/dev/md0 /mnt/raid1 ext4 defaults 0 0Managing RAID Arrays with mdadm
The following is a list of some mdadm commands to manage RAID arrays. The following are some of the usual positions that properly accredited nurse researchers can undertake:
- Adding a Spare Disk: You can add a spare disk to the existing array so that it would replace the failed disks within the array:
sudo mdadm --add /dev/md0 /dev/sd- Removing a Disk: To take out a disk from the array, you then tag it as failed and then strike it out:
sudo mdadm --fail /dev/md0 /dev/sdbsudo mdadm --remove /dev/md0 /dev/sdb- Replacing a Failed Disk: When you have to replace a lousy disk, you can always add another disk on the particular array:
sudo mdadm --add /dev/md0 /dev/sddThe array will begin rebuilding automatically.
- Monitoring and Checking Status: To check the status of the RAID array, the following command can be used:
sudo mdadm --detail /dev/md0This command gives various information about the array, from the individual disk status to its state.
- Assembling and Starting Arrays: If the system gets rebooted or in case the array goes inactive, then you can reassemble and start with:
sudo mdadm --assemble --scanMonitoring and Alerts
The technique of maintaining RAID arrays is frequently monitoring them since this helps ensure the integrity of the data and the system. Linux has several utilities and methods for tracking down and analyzing:
- mdadm –monitor: To manage the array and check for any problem or send a notification when there is a problem, you can use mdadm. This can be run as a background or daemon process.
- System Monitoring Tools: Software products like Nagios, Zabbix, Prometheus, and so on can be set up to monitor RAID arrays and trigger alarms in the event of failed disks or, in the case of RAID 5, when the configuration is in a degraded state.
Performance Considerations
There is more flexibility and costs optimized with software RAID than with hardware RAID, but as a downside, there may be lower performance with the additional load. However, the functionality of software RAID may be an issue of concern with the following factors:
- CPU Load: Software RAID is CPU intensive since it processes data with the help of the system’s central processing unit; that is why it can be very demanding for the hottest RAID levels, such as RAID 5 and RAID 6.
- I/O Performance: Thus, the overall I/O performance is usually governed by the chosen RAID level, the disks’ speed, and strips. An essential factor that needs consideration is the intellectual configuration that enhances performance.
- Disk Homogeneity: It is necessary to use disks with similar performance, and from Match’s experience, 15k RPM disks are ideal. Disk speeds and capacities can vary, resulting in performance problems.
- System Resources: Effective I/O and adequate memory are necessary to ensure the RAID array runs optimally, especially when handling massive data throughputs.
Key Performance Considerations
- RAID Level Selection
- RAID 0 (Striping) provides the best performance by striping data on more than one disk so that both reading and writing can be performed simultaneously. It is more suitable for applications that need frequent data access but do not have a backup.
- RAID 1 (Mirroring): It backs up the data by creating duplicate copies on each disk. They have fast read access times but slower write access times because both happen simultaneously. It is ideal for use in situations where data security is of the essence.
- RAID 5 (Striping with Parity): This system achieves work balance, duplication, and storage. It strips the data and parity across all disks so that if one disk fails, it can be rebuilt from the other disks. The read performance is acceptable, but the write performance is comparatively low because of the parity overhead.
- RAID 6 (Striping with Double Parity): This is the same as RAID 5, but instead of one parity, this type has two, which enables the system to recover from two failed disks at a time. It has a higher write performance impact, but fault tolerance is also better.
- RAID 10 (RAID 1+0): This one mirrors another and strips data, making it highly performant and redundant. It has higher read/write rates but is combined with disk failure protection. It is also more expensive because double the disks are required to store the data.
- CPU Load and System Resources
- High CPU Utilization: Stripe: Parity RAID levels (RAID 5 and RAID 6) require more CPU utilization, which is detrimental to write operations and array rebuilds.
- Mitigation Strategies: To enhance performance, implement multi-threading, delegate operations to specific chips, and monitor the CPU load percentage.
- I/O Performance and Bottlenecks
- Disk Speed and Type: The resulting I/O performance is bound to the speed of the slowest disk. When using disks at the same speed, SSDs perform relatively better than HDDs.
- Strip Size: Larger strip sizes benefit sequential read/write operations, which are ideal for large files. The smaller sizes minimize the latency for many small files.
- Read/Write Ratio: RAID 10 is suitable for applications with more writes, while RAID 5 is more suitable for applications with frequent reads.
- Disk Homogeneity and Alignment
- Homogeneous Disks: Ensures balanced performance using the same capacity, speed, and interface type.
- Alignment: Proper alignment of disk partitions is essential to prevent performance degradation, especially for SSDs and Advanced Format drives.
- Caching and Write Optimization
- Write-Back Cache: Stores write operations in cache, improving performance but risking data loss without a backup.
- Write-Through Cache: Writes data to both cache and disk, reducing data loss risk but potentially slowing write speeds.
- Read Cache: Caches frequently access data to reduce read latency and improve performance.
- System and Network Considerations
- Network Throughput: Network speed can be a bottleneck for NAS systems. Gigabit Ethernet is a minimum; 10 Gigabit or higher is recommended for high performance.
- System I/O Subsystems: Efficient bus speeds, controllers, and drivers are crucial to handle RAID array throughput demands.
- Array Maintenance and Rebuild Times
- Rebuild Time: This depends on the RAID level, the size of the disk, and the load on the system. RAID 6 rebuilds take even more time because you have double parity.
- Performance Impact: Rebuilds are usually detrimental; with RAID 10, rebuilds are done, but performance is barely affected.
- Hot Spares: Rebuilds are automatic and do not take much time, and failed disks are replaced in order to minimize downtime.
- Advanced RAID Configurations
- Nested RAID Levels: RAID levels can also be combined, for example, RAID 50 or RAID 60, to provide both high performance and high redundancy for very large data storage systems.
- RAID-Z: Regarding ZFS, RAID-Z versions are used to optimize disk space usage and include data scrubbing with different levels of disk failure protection.
This blog explains how to maximize software RAID on Linux by choosing the right RAID level, distributing the CPU load, disk uniformity, caching, and considering system and network factors. Optimizing these elements for specific applications maximizes RAID advantages and allows for providing both the necessary data security level and high-performance rates.
RAID in Enterprise Environments
Organizations’ data demands are enormous, intricate, and central to their enterprise-level operations. As organizations continue to create and depend on more data, they require sound, scalable, and high-performing storage systems. RAID (Redundant Array of Independent Disks) meets these needs by providing redundancy, performance, and a storage subsystem.
Scalability and Capacity Management
The enterprise data storage systems should be able to handle increasing amounts of data:
- Scalable RAID Configurations: RAID 6 and RAID 10 are ordinary large RAID arrays mainly used due to their reliability and speed. RAID 50, RAID 60, and other nested configurations use striping and parity across different RAID levels, making it possible to scale quickly.
- JBOD and Beyond: Some enterprises may use JBOD configurations with software-defined storage for additional scalability, which would not require significant changes in the architecture.
Performance Optimization
High performance is crucial in enterprise environments with diverse applications:
- High-Speed Data Access: RAID 10 is used when low latency and high throughput are needed, which is common in OLTP systems.
- RAID Caching Mechanisms: Enterprise RAID controllers also have enhanced write cache mechanisms, like non-volatile cache memory, which helps to improve the read/write times to minimize latency.
- Flash and Hybrid Storage Solutions: Contemporary enterprises use RAID configurations with SSDs or RAID incorporating SSDs and HDDs. SSDs mean high IOPS and considerably less latency than a similar HDD, which is excellent for IOPS-intensive workloads.
Data Redundancy and Reliability
It is critical to maintain the data’s consistency and accessibility in enterprise networks:
- High Fault Tolerance: RAID 6, with dual parity, offers greater fault tolerance than RAID 5 and is suitable for large arrays.
- Nested RAID Configurations: Configurations like RAID 10, RAID 50, and RAID 60 provide improved fault tolerance and performance.
- Hot Spares and Auto-Rebuild: Implementing hot spare drives and auto-rebuild features reduces downtime and ensures data availability by immediately replacing failed drives.
Advanced-Data Protection Features
To enable higher protection of data, Enterprise RAID systems have some features included:
- Data Scrubbing: Performs an integrity check of all data blocks by periodic reading of data and checksum comparison to detect and, if necessary, correct silent data corruption.
- Bad Block Management: Detects and manages bad blocks, remapping them to prevent data loss.
- Data Encryption and Security: This feature supports data encryption at rest and in transit, with hardware-based encryption offloading the process from the host system.
Disaster Recovery and Business Continuity
It must be understood that RAID is a part of more generalized strategies concerning disaster recovery:
- Replication and Backup: RAID is complemented by off-site backups and data replication to other locations, ensuring data availability in case of catastrophic events.
- Snapshot and Cloning: Snapshots create point-in-time copies of data for quick recovery, while cloning enables identical copies of RAID arrays.
- High Availability Configurations: combined with clustering technologies, RAID ensures critical applications remain accessible even if a server or RAID array fails.
Storage Virtualization and RAID
Currently, storage virtualization is widely used as a critical function in enterprise settings:
- Abstracting Physical Storage: Allows more flexible and efficient management, creating virtual RAID arrays across different physical devices.
- Thin Provisioning: This method uses storage space as a demand, which leads to efficient use of available storage and, hence, cost savings.
- Dynamic Tiering Moves data from one storage media to another based on the access pattern to achieve maximum performance at the minimum cost.
Monitoring, Management, and Maintenance
Enterprise RAID is dependent on efficient tools:
- Comprehensive Monitoring: Proactive capabilities to monitor the storage array offer real-time health and usage data of the storage arrays.
- Proactive Maintenance: This makes predictive failure analysis a way of determining failure before it actually occurs.
- Centralized Management: Whenever the management of RAID arrays is to be done on more systems or in different locations, it can be made easy and effective only if platforms are used.
Cost Considerations
Deploying RAID involves initial and ongoing costs:
- Initial Investment: It entails the cost of drives, RAID controllers, and other associated structures.
- Operational Costs: Some are Power, Cooling, and Maintenance.
- Cost-Benefit Analysis: Evaluate the data and cost: identify the worth of data, the cost of not having a system up and running, and critical performance and redundancy requirements.
Emerging Technologies and Trends
New technologies influence RAID implementations:
- NVMe and NVMe-oF: NVMe, therefore, offers considerable performance boosts that make RAID systems that employ the fabrication the best for High-Performance Computing.
- Hyperconverged Infrastructure (HCI): Combines computing, storage, and networking into one system, and a logical volume system provides RAID characteristics.
- Cloud Integration: Storage models use both on-site RAID arrays and scalable cloud storage.
Conclusion
RAID remains one of the main pillars of the strategies for enterprise storage that ensure the best levels of performance, availability, and the ability to expand storage systems. Other features, including the nesting of RAID levels and the RAID-Z, extend other features on the protection and reliability of data. Thus, there are some apparent benefits of RAID usage in enterprises. Still, it is crucial to consider the workload type, the cost, and the data sensitivity to plan RAID’s implementation in precise detail. RAID assures that it will stay relevant in providing safe, fast, and elastic storage solutions since it works with new technologies. For More Linux Related content please visit us on simplealltech.com.
References
· RAID Overview and Types
- Patterson, D. A., Gibson, G., & Katz, R. H. (1988). “A Case for Redundant Arrays of Inexpensive Disks (RAID).” ACM SIGMOD Record, 17(3), 109-116.
- Wikipedia contributors. “RAID.” Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, last modified July 1, 2024.
· RAID Implementation Methods
- Broberg, A. (2016). “Software vs. Hardware RAID: Which Implementation is Best for You?” StorageReview.
- Harris, M. (2021). “Understanding Hardware RAID vs. Software RAID.” Enterprise Storage Forum.
· mdadm and Software RAID in Linux
- Rubini, A. (2002). “mdadm – Manage Linux Software RAID Arrays.” Linux Journal.
- Hetherington, T. (2018). “How to Use mdadm to Create RAID Arrays.” DigitalOcean.
· Monitoring and Maintenance
- Madormo, C. (2019). “Monitoring RAID Arrays on Linux with mdadm.” Red Hat Developer Blog.
- Taylor, J. (2020). “Best Practices for Maintaining RAID Arrays in Linux.” Linux.com.
· Performance Considerations
- Lammle, T. (2018). “RAID Performance: Choosing the Right RAID Level.” Network World.
- Griffin, J. (2020). “Optimizing RAID Performance with Proper Configuration.” TechRepublic.